World models
Links
好像还有另一个发表版本Recurrent World Models Facilitate Policy Evolution (acm.org),但感觉第一个更容易读
github互动论文页:World Models
代码实现:
Pytorch版本: ctallec/world-models: Reimplementation of World-Models (Ha and Schmidhuber 2018) in pytorch (github.com)
Tensorflow版本: zacwellmer/WorldModels: World Models with TensorFlow 2 (github.com)
Video:World Models Explained (youtube.com)
一篇综述文章: arxiv.org/pdf/2403.02622
Notes of World Models (arxiv.org)
01.Introduction
由大脑内部根据过去信息和当前时刻状态对于未来预测并能迅速做出反应引出类比
大脑学习生活中信息的空间和时间方面的抽象表示
任何特定时刻的感知 都受到大脑基于内部模型对于未来的预测 的支配
根据当前运动动作预测未来的感官数据 本能的根据预测模型采取行动
例子:打棒球,根据来球预测未来并迅速挥棒打出快球
传统RL难以学习大模型数百万权重[信用分配问题],较小网络能在训练更快迭代到一个好的策略
将智能体分为大型世界模型和小型控制器模型,训练大型NN来处理RL任务
训练大型NN 无监督学习智能体的世界的模型 而训练较小控制器模型[专注于小搜索空间的信用分配问题]学习使用世界模型执行任务
PS: 还探索了将实际的环境完全替换为生成的环境
02.Agent model
Agent(有视觉感知)---->看到内容压缩为编码---->根据历史信息预测未来状态---->根据V和M作出行动决策
V M C
视觉(V) 记忆(M) 控制[决策]器 (C)

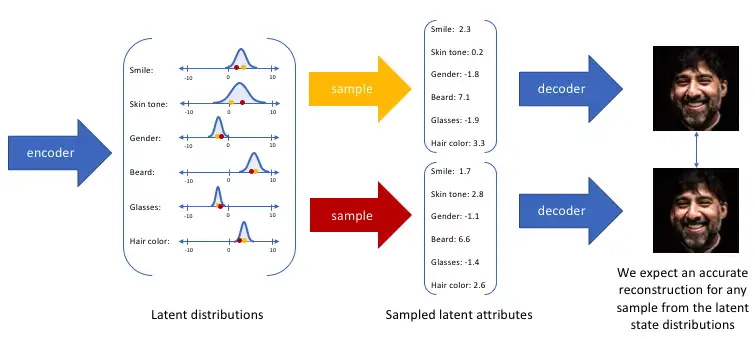
V----VAE model
作用:学习每个观察到的输入帧的抽象压缩表示,进行encode
变分自编码器:
一文理解变分自编码器(VAE) - 知乎 (zhihu.com)
输入高维数据---->编码产生概率分布----->隐向量z------>解码使用概率分布的采样
M----MDN-RNN
作用:预测未来
因为许多复杂的环境本质上是随机的,所以训练 RNN 输出概率密度函数\(p(z)\)而不是z

对\(P(z_{t+1}|z_{t},a_{t},h_{t})\)建模:\(a_{t}\)为时刻t采取的动作,\(h_{t}\)是RNN的隐藏状态(包含了过去的信息)
\(τ\)是temperature参数(控制预测z时候的采样分布,τ越高对未来预测越随机化)
C----Controller Model
作用:确定要采取的操作action,以便在环境推出期间最大化智能体预期获得奖励
特点:C尽可能简单和小,为了使得大部分复杂性和模型参数位于V和M中
使用了单层线性模型将\(z_{t}\)、\(h_{t}\)映射到\(a_{t}\)
C参数优化策略:CMA-ES
V&C&M together

03.赛车实验
3.1实验步骤
Step1. 收集10000个随机环境的数据集
Step2. 训练VAE把帧编码为z向量
Step3. 训练MDN-RNN以对\(P(z_{t+1}|a_{t},z_{t},h_{t})\)进行训练
Step4. 定义控制器C \(\(a_{t}=W_{c}[z_{t},h_{t}]+b_{c}\)\)
Step5. 使用CMA-ES 优化参数w、b使得期望累计奖励最大化
3.2 结果
文章分了三种情况,只看V,加了一层hidden,以及完整的模型,效果逐渐变好
-
只有V\C驾驶 不稳定
-
允许智能体同时访问V、M提高稳定性,有效急转弯
进一步的想法:生成赛程场景 && 在幻想(预测的内容)中训练
04.VizDoom实验
躲避特工的小游戏实验

实验中发现了一个问题,智能体会==“欺骗”模型==,发现对抗策略---->解决方案是提升\(τ\),但要适度提升,否则效果变差
05.迭代训练
只有智能体学会如何有策略的在世界中导航才能获得世界的一部分
上面的实验比较简单,但更复杂的任务需要迭代训练过程,防止random参数学习到的内容不够好(有缺失)
迭代训练类似“大脑重放最近的经历”
附录----一些内容的实现细节
1.变分自编码器VAE
2.RNN
3.控制器
4.进化策略(CMA-ES)
5.DoomRNN
Applications
1.数据稀缺问题---场景生成、在模拟环境中训练
GAIA DriveDreamer等
在自动驾驶领域,世界模型的引入标志着向数据驱动智能的关键转变.
数据稀缺性问题,特别是在如BEV标注等专业任务中,突显了世界模型等创新解决方案的实际必要性。通过从历史数据中生成预测情景,这些模型不仅规避了数据收集和标注带来的限制,还增强了在模拟环境中训练自动系统的能力,这些环境可以反映甚至超越现实世界条件的复杂性。
例如:某些驾驶行为由于其==风险性难以获取数据==,驾驶场景生成允许模拟测试
凭借自动驾驶车辆采集的大量实景视频数据,可以利用生成模型 去生成未来场景来和真实的未来时刻数据对比,从而构建loss,这样就可以不依赖标注信息对模型进行训练
2.规划与控制
MILE DriveWM等
在自动驾驶领域,世界模型通过==模拟车辆在各种交通环境中的行为和互动来增强决策和规划能力==。它们能够预测其他车辆、行人和动态环境变化,从而帮助自主系统做出更安全、更高效的驾驶决策。例如,在无人驾驶汽车项目中,世界模型可以预测交通流量、路况变化以及潜在的风险因素,使车辆能够提前做出反应,避免事故和优化行驶路径。
Problems
- 训练数据需求大,处理数据消耗时间资源高
- 模型==可解释性==在医疗、自驾领域有待提高,可能带来潜在风险
- ==计算资源需求==高,需要处理高维数据、复杂环境
- 还有一些决策责任、==隐私伦理==方面的问题
Related Works
相关的一些研究也大致是重点分别在数据生成和规划控制决策两个应用分类上,也有部分研究都有涉及
01.BEV预测(百度)
主要工作:使用==多模态的数据==(视角图像、雷达)转换到==BEV表达进行预测未来的图像和点云==
是多模态的世界模型,多模态数据--->BEV--->未来预测
分为两个主要部分 PART1.多模态tokenizer网络、 Part2.潜在BEV序列扩散网络
tokenizer将原始多模态数据压缩在BEV空间
扩散序列用来预测未来帧图像和点云
局限:扩散模型推断过程缓慢且计算成本高,动态对象生成图像模糊


02.SEM2
语义掩码世界模型
针对的问题:潜在状态中包含的无关信息(天气、楼等)导致采样效率低、鲁棒性差,训练数据分布不均
效果:提升端到端自动驾驶的采样效率和鲁棒性
主要特点
decoder加入了语义掩码,使得模型学到 更紧凑 & 与驾驶任务更相关的 特征
针对训练数据不均衡:在每个训练batch加入各种场景样本来均衡分布
- 输入端除了视频序列内容还加入了lidar信息
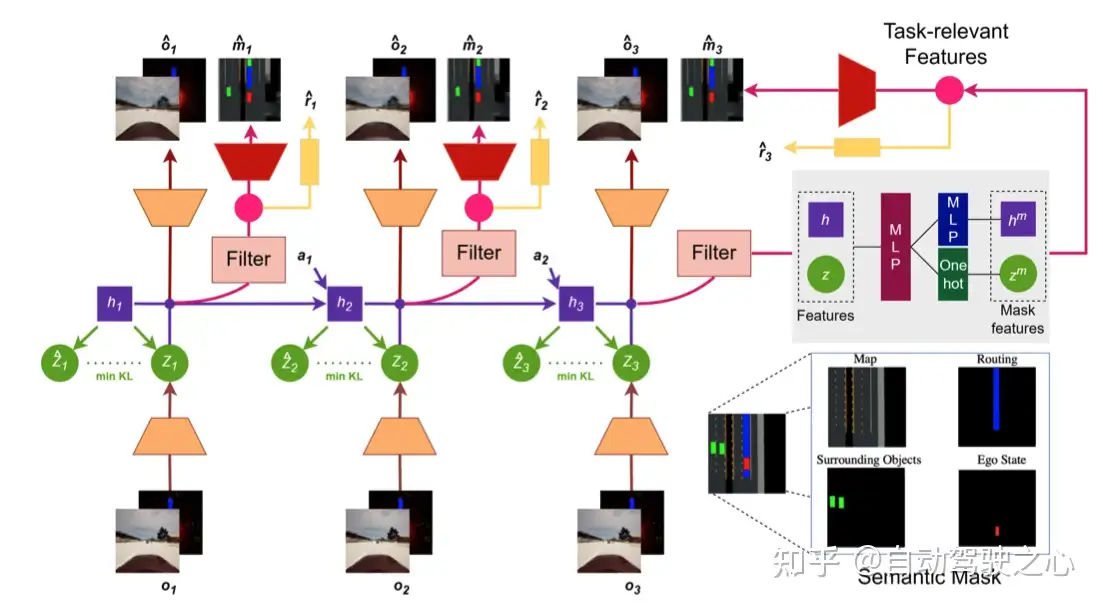
03.Wayve公司的研究工作MILE
[2210.07729] Model-Based Imitation Learning for Urban Driving (arxiv.org)]
MILE中==没有预测reward== 基于==模仿学习== 有==action的输出==
将世界模型与模仿学习相结合,从离线驾驶数据语料库中联合学习世界模型和驾驶策略,想象多样化和合理的未来,并利用这种能力来想象如何规划其未来的行动。。甚至==在“想象”中驾驶==
使用“广义推理算法”进行理性和可视化的未来驾驶环境的想象和预测,通过想象来弥补感知信息的缺失
使未来action的规划成为可能,允许自动驾驶车辆在没有高清地图的情况下操作
主要结构:
- 观测编码:图像特征 提升3D,汇总BEV,提取特征压缩为一维向量
- 概率建模:预测的将要发生的情况与实际发生情况分布的匹配训练
- 解码器:输出图像、bev的重构以及驾驶策略
- 时间建模:循环网络、对潜在动态建模,从前一个潜在状态h预测下一个
- imaging想象:结合过去及观察,想象未来的潜在状态,进行规划和操作,或者也能通过解码器可视化

04.GAIA 场景生成预测
[2309.17080] GAIA-1: A Generative World Model for Autonomous Driving (arxiv.org)
通过==多模态数据输入==生成==高质量==的驾驶场景,如视频、文字
特点:自监督学习 多模态数据处理
结构:世界模型+视频扩散编码器
- 训练encoder 将视频、文字、行为(速度、转向等action)转换为token
- world model训练,对序列产生预测(随机drop一些token适配不同的生成)
- 预测decoder,将产生的latent序列解码为视频内容

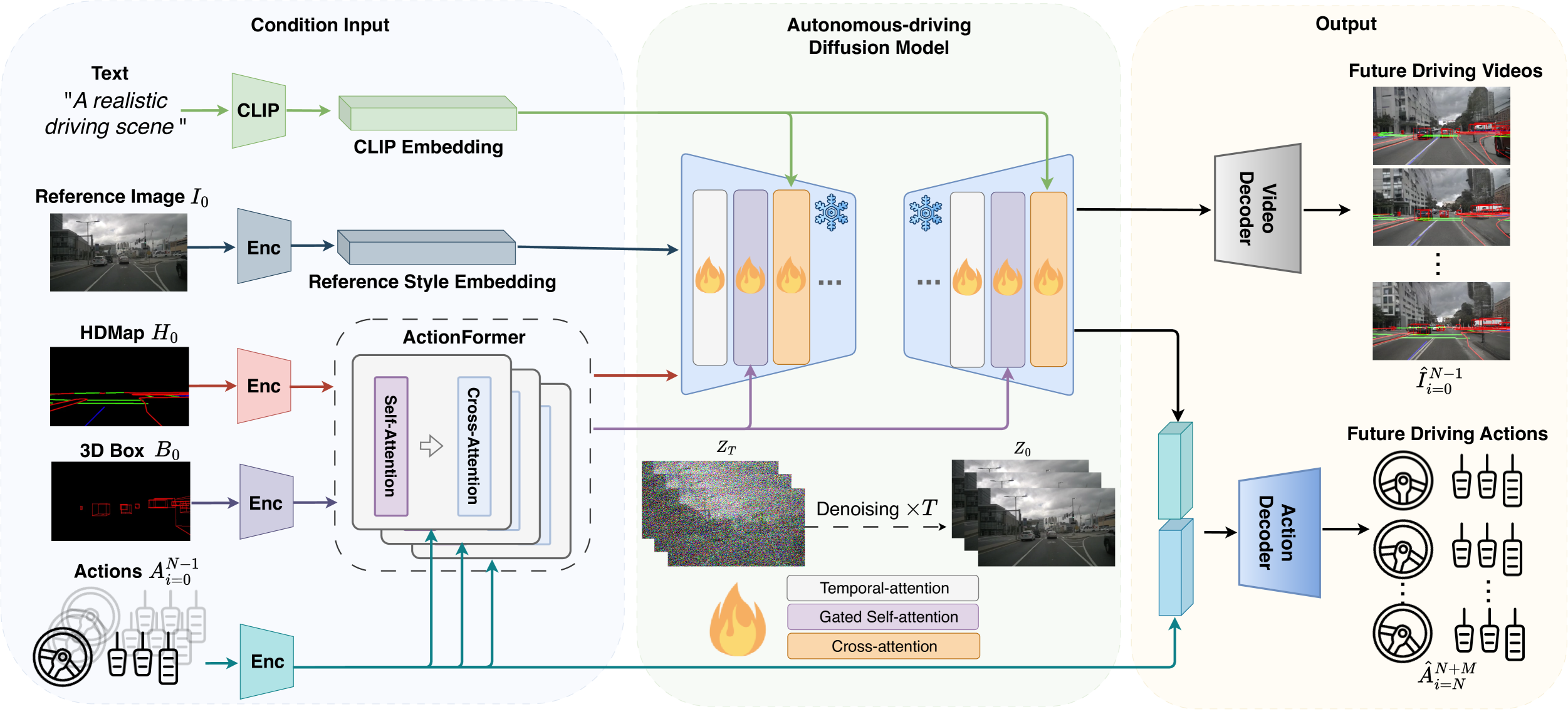
05.DriveDreamer (清华)
完全==源自真实世界驾驶场景==的world model,在nuscenes上做了训练,输入包括了更多的元素
连续驾驶视频生成、驾驶场景交互、根据驾驶动作输入预测未来
侧重驾驶策略生成,除了场景还能生成未来驾驶动作,更具有决策性
两阶段的训练:
- 增加视频生成中不可控的表现
- 引入actionFormer使用驾驶动作迭代预测未来,减少干扰,提高accuracy
还有一个 DriveDreamer-v2 (中科院),结合了一个LLM来生成用户定义的驾驶视频
DriveDreamer的结构:
06.Drive-WM
用于增强==端到端==自动驾驶规划安全性的==多视角==世界模型
联合多个视图多个帧:
图像形式化----->加入时间层----->多视图编码
通过多视角和时间建模,共同生成多个视角的帧,然后从相邻视角预测中间视角,提 高多个视角之间的一致性
利用世界模型为从planner中采样的轨迹候选项生成预测的未来场景,使用基于图像的奖励函数评估未来场景,并选择最优轨迹来扩展规划树
后面的细节结构内容有点没看太明白,但主要特点是首个实现端到端世界模型潜在应用的,而且融入了多视角。文章称效果很好

07.TrafficBots
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
端到端 运动预测 多智能体策略
强调场景中代理的动作预测
使用世界模型解决数据驱动的交通模拟问题
更快的操作速度,可以扩展以容纳更多代理
采用CVAE编码器学习每个agent的独特个性,促进动作预测从BEV角度进行
应用:交通模拟、运动预测
与world model关系 :
"我们寻求获得一个足够真实的世界模型,以取代现实世界或全栈模拟器来开发 AD 规划算法。"(原文翻译)
08.Think2Drive(上交)
用于准现实的交通场景 或者作为数据收集模型
使用世界模型来学习环境的变化,然后用它充当神经模拟器来训练planner
由于世界模型可以在低维潜在空间思考,模型有较高训练效率
==直接利用3D占用信息作为系统输入==来预测周围环境的变化并规划自动驾驶车辆的action
主要的内容:
记录采样--->世界模型编码\(s_{t}\)--->规划生成\(a_{t}\),\(s_{t}\)和\(a_{t}\)输入预测奖励\(r_{t}\),终止状态\(c_{t}\)和未来\(s_{t+1}\)
使用DreamerV3结构和目标训练世界模型和planner
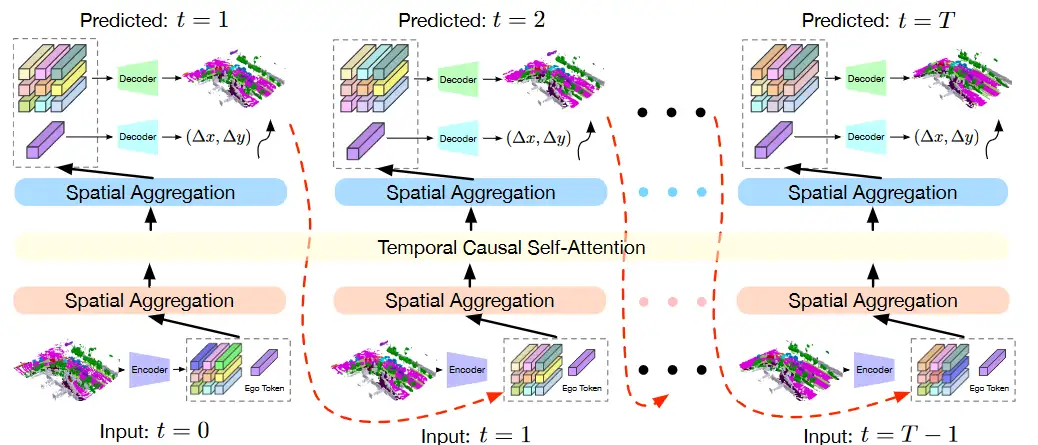
09.OccWorld(清华)
在3D空间学习world model
“自动驾驶场景的自回归生成建模框架”
基于==3D占有率(occupancy)==(原因:场景描述更精细、获取更经济、可以同时适应视觉和雷达)
主要内容:
- 使用3D占用表示来描述周围环境,将3D空间划分为多个体素,并为每个体素分配占用标签
- 通过自监督的方式将3D占用转换为离散的场景标记,以便更好地表示场景
- 采用空间-时间生成变换器来预测未来的场景标记和自我运动轨迹,模型能够在多个尺度上进行空间聚合和时间注意力机制的应用
一个网友推荐的world model做未来场景预测的文章 源自ICLR2024

LEARNING UNSUPERVISED WORLD MODELS FOR AUTONOMOUS DRIVING VIA DISCRETE DIFFUSIO
d12a0fed-b821-4dbc-835e-8d1a34304f8f.pdf (baai.ac.cn)
首先使用VQVAElike标记器对传感器观测进行标记,然后通过离散扩散预测未来。该标记器将点云编码为鸟瞰图(BEV)中的离散潜点,并通过可微深度渲染进行重建
提出将观察标记化、离散扩散和Transformer架构结合起来,作为构建无监督世界模型的新方法,从而为自动驾驶中的点云预测任务获得最先进的结果

开头的Links里面放的那篇综述里面有一个很好的图
总结了与world models有关的研究
