Transformer
Transformer
Sequence to Sequence (Seq2seq)
输出长度由模型决定
Encoder-Decoder结构
Encoder

原始的Transformer结构:

改进:https://arxiv.org/abs/2002.04745
为什么layer norm:https://arxiv.org/abs/2003.07845
Decoder
Masked:按顺序,只考虑前面的影响
- Masked Multi-Head Attention 与encoder部分相比,有所改变
- encoder可以拿到整个sequence,因此可以考虑全局
- 而decoder只有前文,因此只会考虑出现过的向量(因为根本不存在)
Autoregressive vs. Non-Autoregressive
- 上面的内容被称为自回归
- 非自回归:一次性喂入多个begin进行预测
- 方便控制长短
- 使用另一个分类器进行长度预测(对输出长度再做一次乘法、乘法,能直接调整)
- 或生成足够数量的token,查看第一个end
- 方便并行
- 效果会更差

Cross Attention
encoder 与decoder交互
q来自decoder,k、v来自encoder

Training
- 看作一个分类问题,使用交叉熵损失函数
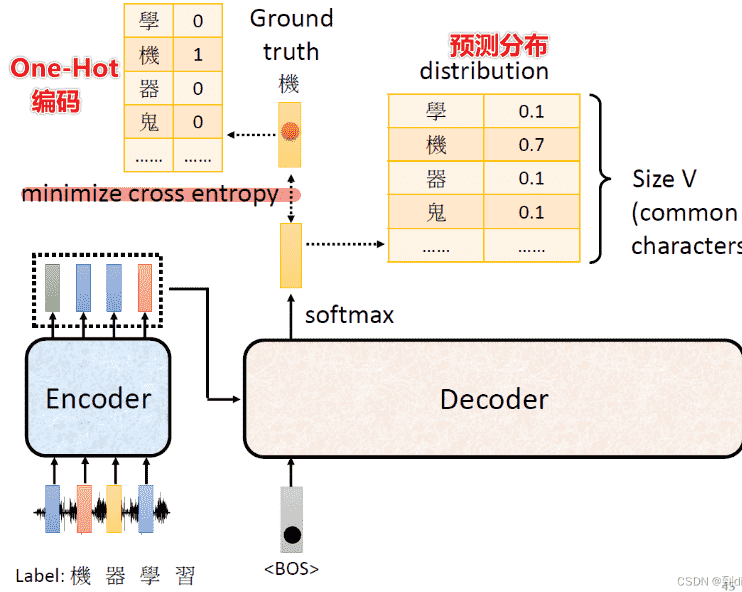
-
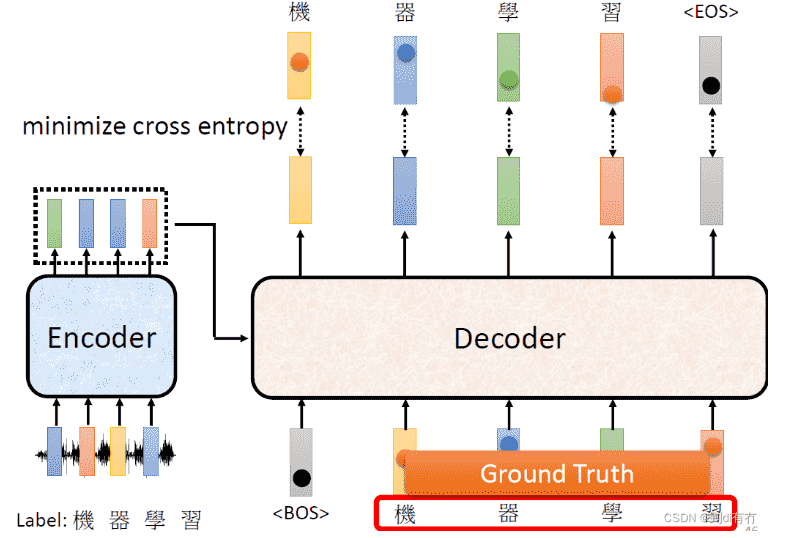
但是我们需要强制喂入Decoder正确的输入,只有这样才能进行比较
-
即我们不会每次把Decoder的输出作为新的输入,而是直接设定好
-
这个过程叫做
Teacher Forcing
- 在训练的时候进行Teacher Forcing,最后的误差自然会偏低
-
而在做测试时是无法做到的,造成mismatching
-
EOS也需要被当作预测字符进行预测
Tips:
Copy Mechanism
无需decoder输出,直接从输入复制一些东西进来
如:人名
摘要
Guided Attention
语音辨识、语音合成
- 对输入输出(Attention)进行指导
Beam Search
 需要机器发挥创造力就不要用了
需要机器发挥创造力就不要用了
优化过程中,对于很难微分的函数计算,我们可以考虑使用强化学习
exposure bias
在训练时decoder输入都是正确的ground truth但测试时有可能得到错误输入
Scheduled Sampling:我们在喂入decoder的时候,故意弄错一点东西(引入噪声)
